In my last blog I introduced the concept of a “Business Process Service Architecture – BPSA“. This architectural style can be used to design a business process running in a microservice architecture, even when all services are decoupled strongly as single verticals.
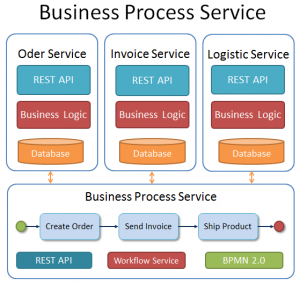
The idea of this concept is, that a separated microservice is running the “Overall-Business-Process” decoupled from the verticals. The business process reflects the workflows implemented in the organisation of an enterprise. These workflows may also be often non-technical and human-centric. For example, the shipment of a product is usually performed manually, but also impacts the technical layers. So the question is: How can we coordinate our vertical service layers to align them to an “Overall-Business-Process”?
I want to explain the concept of BPSA first on a scenario which I visualize with the help of BPMN 2.0. The scenario is based on the example that I used in my first blog. The BPMN model I show here, was created with the Eclipse modelling Tool Imixs-BPMN, but first of all, this model is independent of the later used workflow engine.
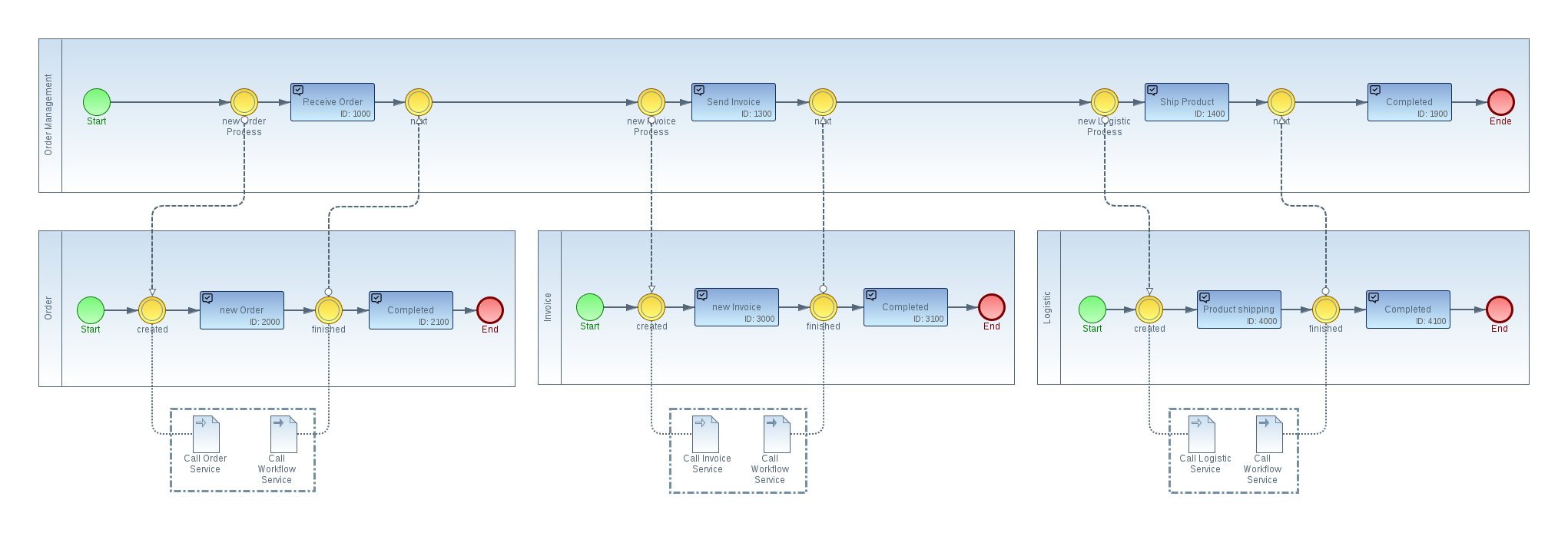
The Model shows four different workflows. One workflow for each vertical and the “Order Management” Workflow which reflects the Overall-Business-Process. The model is kept very simple to only show the key facts of the concept.
Starting a New Process Instance
The business logic of a vertical does not happen by itself. There is typically always a triggering event that starts the business process. In our example, this is the reception of a new order. A new order can be received manually by a phone call or an E-Mail, or automatically triggered by another IT system, e.g. a online shop software. So once a new order is received, we start a new instance of the “Order Management” Process with the task “Receive Order”. The BPMN event “new Order Process” immediately starts the sub-process called “Order”, which is presenting the micro-workflow of the vertical ‘Order Service’. This sub-process can for example callback the microservice to create a new order dataset in a database.
But this is not necessary the only way to start the process. It is also thinkable that the Order Service will start the “Order Management” Process by itself because it’s the piece of software receiving the order details. Or for example the external IT system could trigger both verticals – the “Order Service” and the “Order Management” Process. The important thing here is, that after we received a new order we start a new Instance of the “Order Management” Process which is triggering the other involved sub processes.
So when we go back to the model example, now we have two new process instances – the “Order” which reflects the status of the vertical “Order Service” and the “Order Management” process which indicates the status of the general enterprise business process. Both processes are tightly coupled, which corresponds to the enterprise business process. On the other hand, the workflow service itself may be loosely coupled to the verticals, e.g. by a asynchronous reactive programming style.
Monitoring the Business Process
Once a new instance of the “Order Management” Process was started, we can now monitor the process including the status of its sub-processes. For example a Workflow Management UI can provide the sales manager with status information about current orders. This person has typically a high-level view on the process with is reflected by the“Overall-Business-Process”. But also a back-end monitoring system can use the workflow service, for example to control the load of expected records in different databases. In both cases the workflow model can be extended with different tasks to detail the status of each process layer.
The Control of the Process
The interesting part of the example which I illustrate here, is how the process can be controlled by a microservice. As shown in the BPMN model, each vertical has its own sub-process model. And only the vertical assigned to a specific sub-process is allowed to trigger an event inside this process. The “Workflow Service”, on the other hand, controls and verifies the consistency of the business process along the BPMN model.
In our example the “Order Service” may trigger the event “finished” of the “Order” workflow once the service has created the order-record in an order-database. This event will immediately change the status of the “Order Management” Process from “Receive Order” to “Send Invoice”. As a result of this status change, a new sub-process assigned to the “Invoice Service” will be created by the “Wokflow Service”.
As the order sub-process is now completed, the OrderService will no longer be able to send the “finished” event to the WorkflowService. A workflow engine will typically throw an exception in case a process tries to trigger irregular events. As each vertical can also monitor its assigned sub-process, each microservice can read the model to check the internal status and possible events to be triggered. As a result the typical business logic of a microservice to verify an internal business model can be reduced dramatically. For example we can design each sub-process in a generic style and always provide an event for a success-case and an error-case.
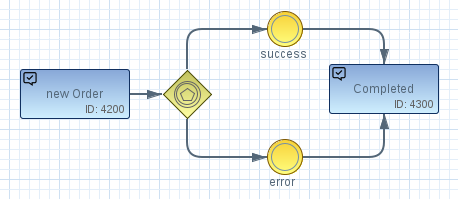
The benefit is that we can now control the process fully by the WorkflowService and decouple the service from the business logic. On the other hand a human actor may also be involved in the main process model. For example a warehouseman will be informed by E-Mail from the workflow engine that he have to confirm the shipment of the product. He can manually trigger a corresponding action from the Workflow Management UI. As a result of such a manual event the workflow engine may trigger another microservice.
How to Change the Process
In a productive environment, a sub-process will possible consist of a lot of different tasks and events, which can be triggered by the assigned vertical and monitored by different actors. Also the “Order Management” Process will typically contain more events to control the process in various ways. For example the sales manager may be able to trigger a “Cancel” event to stop the order management process. This status change would immediately affect all sub-processes which will be disallowed to send any further events to the main-process.
The advantage of this concept is, that the process models can be changed during runtime, without the need to change the implementation of a single vertical. This makes the concept strong and flexible and takes care about the typical business needs of a changing enterprise – an agile organisation.
Conclusion
Of course, the implementation of a Business-Process-Service-Architecture can be tricky in various details. Much of what is today typically hard-coded in the business logic of a microservice will be now transferred into a process model. For this purpose, also experiences with BPMN are required. But the effects of BPSA can be impressive, especially when the workflow engine itself covers a lot of the business logic. For example, a human-centric workflow engine like the open source project Imixs-Workflow, can send E-Mail messages, provide a process history, or distributes tasks to different actors to be involved in the process. Finally the microservices become smaller and can now indeed decoupled from each other.