
If you play around with Apache Hadoop, you can hardly find examples build on Docker. This is because Hadoop is rarely operated via Docker but mostly installed directly on bare metal. Above all, if you want to test built-in tools such as HBase, Spark or Hive, there are only a few Docker images available.
A project which fills this gap comes from the European Union and is named BIG DATA EUROPE. One of the project objectives it to design, realize and evaluate a Big Data Aggregator Platform infrastructure.
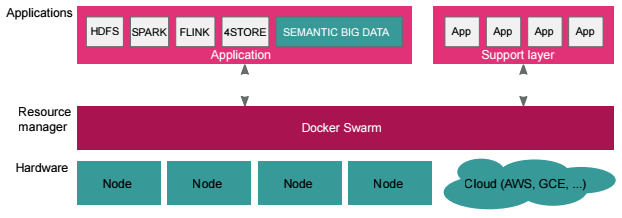
The platform is based on Apache Hadoop and competently build on Docker. The project offers basic building blocks to get started with Hadoop and Docker and make integration with other technologies or applications much easier. With the Docker images provided by this project, a Hadoop platform can be setup on a local development machine, or scale up to hundreds of nodes connected in a Docker Swarm. The project is well documented and all the results of this project are available on GitHub.
- The project BIG DATA EUROPE
- General platform description
- Big Data Europe on GitHub
- Big Data Europe an Docker Hub
For example, to setup a Hadoop HBase local cluster environment takes only a few seconds:
$ git clone https://github.com/big-data-europe/docker-hbase.git $ cd docker-hbase/ $ docker-compose -f docker-compose-standalone.yml up Starting datanode Starting namenode Starting resourcemanager Starting hbase Starting historyserver Starting nodemanager Attaching to namenode, resourcemanager, hbase, datanode, nodemanager, historyserver namenode | Configuring core resourcemanager | Configuring core ......... ..................