Since July 2025 the old oss repositories (e.g. https://oss.sonatype.org/content/repositories/snapshots) are deprecated and are no longer accessible. If you have not yet updated your Maven Open Source project you need to change some settings. But most things are now more easy as before.
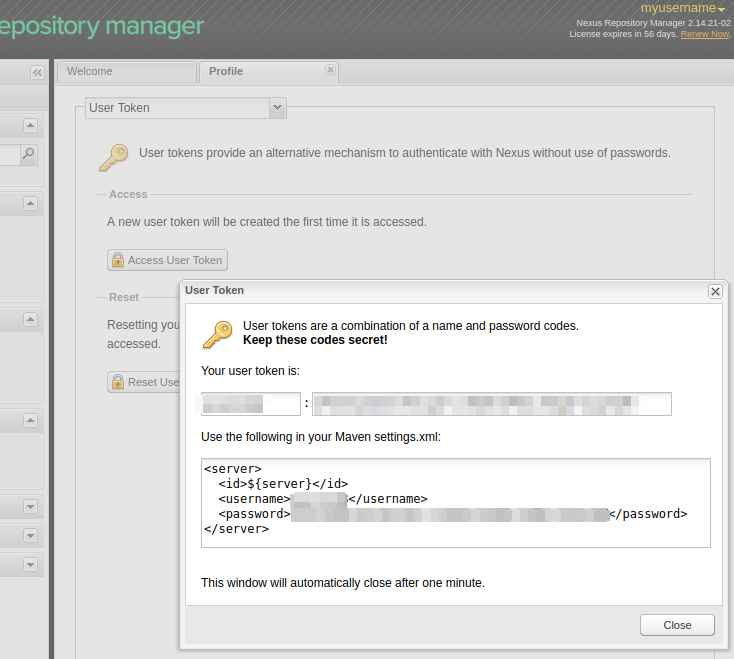
1. Create a new User Token
If you do not have yet generated a User Token, open your Sonatype Account:
https://central.sonatype.com/account
and generate a new User Token.
Next update your maven settings.xml file (e.g ~/.m2/settings.xml) with your generated username and password token:
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<servers>
<server>
<id>central</id>
<username>....</username>
<password>.............</password>
</server>
</servers>
</settings>
No additional settings regarding the server URLs are needed here.
Note: If you generate a new user token/password it can take a while until the new credentials are synchronized and active. So if you see the following error message this can also be an issue that the new credentials are not yet active and you need to wait a few minutes:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:2.7:deploy (default-deploy) on project imixs-marty: Failed to deploy artifacts: Could not transfer artifact org.imixs.workflow:imixs-marty:jar:5.1.1-20250707.205537-1 from/to central (https://central.sonatype.com/repository/maven-snapshots/): authorization failed for https://central.sonatype.com/repository/maven-snapshots/org/imixs/workflow/imixs-marty/5.1.1-SNAPSHOT/imixs-marty-5.1.1-20250707.205537-1.jar, status: 403 Forbidden -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException2. Update your pom.xml File
Next update your pom.xml. The new setup is much simplified. The main issue is to replace the old nexus-staging-maven-plugin with the new central-publishing-maven-plugin.
Here is an example with the important parts:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>.....</groupId>
.............
<repositories>
<repository>
<id>central-portal-snapshots</id>
<name>Central Portal Snapshots</name>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<build>
<plugins>
..........
<!-- release management -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-release-plugin</artifactId>
<version>3.0.1</version>
<configuration>
<autoVersionSubmodules>true</autoVersionSubmodules>
<useReleaseProfile>false</useReleaseProfile>
<releaseProfiles>release</releaseProfiles>
<goals>deploy</goals>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-site-plugin</artifactId>
<version>3.12.1</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-javadoc-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<additionalOptions>-Xdoclint:none</additionalOptions>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jxr-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<!-- java doc -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-javadoc-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<additionalOptions>-Xdoclint:none</additionalOptions>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jxr-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</reporting>
<profiles>
<!-- Profile for Releases -->
<profile>
<id>release</id>
<build>
<plugins>
<!-- for RELEASES: Central Publishing Plugin -->
<plugin>
<groupId>org.sonatype.central</groupId>
<artifactId>central-publishing-maven-plugin</artifactId>
<version>0.8.0</version>
<extensions>true</extensions>
<configuration>
<publishingServerId>central</publishingServerId>
<autoPublish>true</autoPublish>
<waitUntil>published</waitUntil>
</configuration>
</plugin>
<!-- Source Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<id>attach-sources</id>
<goals>
<goal>jar-no-fork</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- Javadoc Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-javadoc-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<additionalOptions>-Xdoclint:none</additionalOptions>
</configuration>
<executions>
<execution>
<id>attach-javadocs</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- GPG Signing Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-gpg-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<id>sign-artifacts</id>
<phase>verify</phase>
<goals>
<goal>sign</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
</profiles>
<dependencies>
.............
</dependencies>
<!-- Distribution Management central.sonatype.org -->
<distributionManagement>
<snapshotRepository>
<id>central</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
</snapshotRepository>
<repository>
<id>central</id>
<url>https://central.sonatype.com</url>
</repository>
</distributionManagement>
</project>I left the parts ‘url’, ‘scm’, ‘licenses’ , … here. You need to fulfill the requirements for a correct project documentation in your pom.xml
3. Deploy your Snapshot
To deploy your snapshot version just use the same command as before:
$ mvn clean deploy To check your snapshots you can’t any longer browse the sonatype snapshot repos with your browser. But you can request a specific snapshot URL to test if your upload was successful. E.g.:
4. Release
To release your project you can run:
$ mvn release:clean release:prepare -DautoVersionSubmodules=true
.....
$ mvn release:performThat’s it.