
In the following I will share my thoughts about how to setup a PostgreSQL Database in Kubernetes with some level of high availability. For that I will introduce three different architectural styles to do this. I do not make a recommendation here because, as always every solution has its pros and cons.
1) Running PostgreSQL Outside of Kubernetes
In the first scenario you run PostgreSQL outside form Kubernetes. This means Kubernetes does not know anything about the database. This situation is often a result of a historical architecture where PostgreSQL was long before Kubernetes in an evolving architecture.
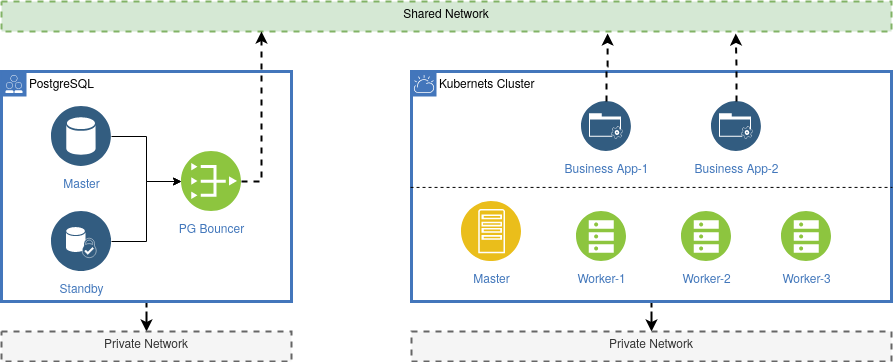
The challenge here is that you need a deep understanding of how to install and setup PostgreSQL. The PostgreSQL cluster consists of a Master Node and a Standby Node. In case the Master Node failed for some reasons (e.g. a hardware or network defect) the standby server can overtake the role of the master. The PG-Bouncer in this picture is a component from Postgres and acts as a kind of reverse proxy server. In case of a failure the switch form the Master to the Standby node can be done by a administrator or can be automated by scripts. From the view of a client this switch is transparent.
From the perspective of Kubernetes the PostreSQL database is just an external resource which is not under control from Kubernetes. A business application running on a POD in Kubernetes connects directly via a public or shared network to the PG-Bouncer. If the PostgreSQL Database is not reachable for some reason, Kubernetes can do nothing about this. So in this case you need some kind of additional monitoring.
2) Running PostgreSQL Inside of Kubernetes
In the second scenario you run the PostgreSQL Cluster inside of Kubernetes. The Postgre- master- and standby-nodes as also the PG Bounder are now running on PODs inside the Kubernetes Cluster. There are a lot of tutorials how to setup and deploy PostgreSQL in Kubernetes. The crunchy data project provides a open source deployment configuration for Kubernetes.
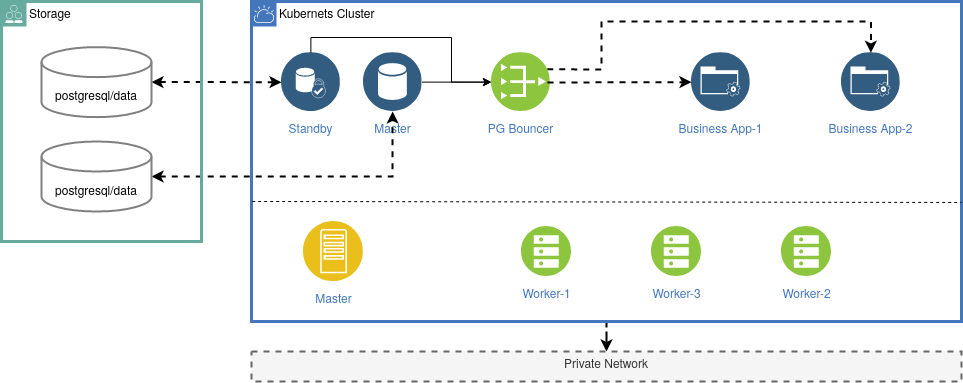
The failover control of the Master and Standby PODs can now be handled by Kubernetes – e.g. with Kubernetes Operators. Your business application still connects to the PG-Bouncer which is now running on a POD inside Kubernetes. All the communication is now handled by the internal network of Kubernetes.
The difficult part here is the storage. Kubernetes did not provide storage by itself, but it provides a lot of solutions based on the container storage interface (CSI). You need to setup a storage solution by yourself – either running inside your Kubernetes cluster or as a external solution. And of course you still need a good understanding of PostgreSQL and the Kubernetes Operator concept.
3) Running PostgreSQL on a Distributed Block Storage
So far both solutions were based on the HA concept of PostgreSQL using a PG-Bouncer and Master and Standby nodes. In both cases you need a good understanding of PostgreSQL and you need to either setup PostgreSQL on a separate infrastructure or you need to provide a Kubernetes storage solution.
My last architectural concept is a more lightweight approach which first focus on the question about storage. The storage problem in Kubernetes need to be solved anyway, independent of the question if you run a PostgreSQL database or not. Most applications need some kind of persistence volumes. For examplem WordPress expects not only a database but also a filesystem to store the media content. So storage should always be solved first if you start with Kubernetes. As explained before, Kubernetes provides a lot of concepts how to deal with storage and the so called persistence volumes.
A common solution is a distributed block storage like provided by the open source projects Longhorn or Ceph. Both systems integrate well into Kubernetes and can be setup easily. If you have already connected such a distributed block storage with your Kubernetes cluster, running a PostgreSQL database can become quite simple:
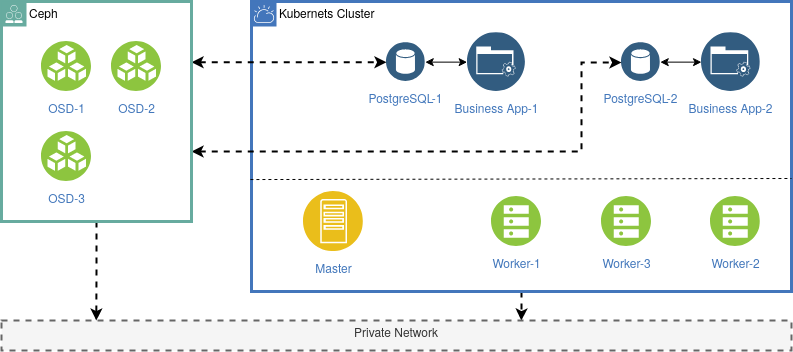
In this scenario each business application has its own PostgreSQL Database running in a POD. The data volume is provided by a Ceph storage system using the Ceph CSI plugin. Kubernetes controls the PostgreSQL POD and the storage volume. If a OSD or block device in Ceph has a failure, this is handled by the Ceph cluster and Kubernetes will react on failures thanks to the container storage interface (CSI). If something in Kubernetes get wrong (e.g. a failure of a worker node) Kubernetes will reschedule the PostgreSQL POD internally. With a Liveness and Readiness Check you can monitor your PostgreSQL database:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
labels:
app: postgres
spec:
replicas: 1
selector:
matchLabels:
app: postgres
strategy:
type: Recreate
template:
metadata:
labels:
app: postgres
spec:
containers:
- env:
- name: POSTGRES_DB
value: mydb
- name: POSTGRES_PASSWORD
value: xxxx
- name: POSTGRES_USER
value: myuser
image: postgres:9.6.1
name: postgres
# Readiness and Liveness Probe
readinessProbe:
exec:
command: ["psql", "-Umyuser", "-dmydb", "-c", "SELECT 1"]
initialDelaySeconds: 10
timeoutSeconds: 10
livenessProbe:
exec:
command: ["psql", "-Umyuser", "-dmydb", "-c", "SELECT 1"]
initialDelaySeconds: 30
timeoutSeconds: 10
ports:
- containerPort: 5432
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: dbdata
subPath: postgres
restartPolicy: Always
volumes:
- name: dbdata
persistentVolumeClaim:
claimName: dbdataConclusion
As I said in the beginning, I don’t want to make any recommendations, as every architecture has its pros and cons. You have to think about what High Availability (HA) means to you and your project. PostgreSQL itself is very robust and stable and running it as a service in a single Kubernetes POD is a valid solution. In combination with a distributed block storage this can be a lightweight and stable solution. If you already have a PostgreSQL HA Cluster up and running, use it and don’t try to squeeze everything into Kubernetes.
One Reply to “PostgreSQL HA & Kubernetes”